few hit AI apps exist because LLMs are what i’d call very “strangely-shaped” tools.
most tools are built with a specific purpose in mind like a screwdriver or a car.
but LLMs were something we stumbled upon by predicting text and playing with RL – we didn’t design the shape of them beforehand, we just let them naturally evolve into what the loss optimized for.
it’s clear they’re good at many things, but they are so strangely shaped that it’s easy to fall into traps when making products.
AI agents are a good example of a trap (for now), where it’s easy to spend months trying to perfect your scaffolding yet never quite reaching the level of reliability you’d hope for.
long-term memory implemented solely via RAG is another trap. it’s just tempting enough to try, but the results aren’t as good as they should be.
other common inadequacies include poor search, hallucinations, and high inference costs. but there’s a long list of subtle weaknesses which few tinkerers ever notice as well as many weaknesses (and strengths) which remain unfound.
much of the frontier of LLM posttraining is currently concerned with these inadequacies – wondering how we can mold these strangely-shaped LLMs we have grown into a slightly more suitable form for the problems we face.
this is hard, even for the major labs. as we slowly progress on it, i’d expect to continue to see most AI products attempt to solve the same problems via the same methods, further suffering from lack of distinctness both in performance and aesthetic, because they don’t have the right connection between research teams and product teams (or perhaps the right vision to begin with).
it’s telling that among the few recent consumer successes like midjourney or perplexity, competitors are hyper-focused on directly copying winners rather than exploring the vast new frontier of things which could be built instead. this makes sense because the frontier is strangely-shaped, as a result of the underlying catalyst itself being strangely-shaped.
it’s not uncommon for services to launch a feature literally called “AI” which is primarily composed of literal magic wands and glitter emoji simply because the product designer has no idea how to actually convey the intended experience to the user. 2024 is certainly not a year one would be fired for using too much AI.
I expect it to get more interesting later this year and especially in 2025, but it’s still been a surreal experience continually contrasting my day to day life in san francisco with that of the actual real world (note: SF is not real in this example).
the above is also relevant to some of the reasons i have longer agi timelines than i did a few years ago. agi is not a strangely-shaped tool. in fact, it is quite literally the opposite.
The bouba/kiki effect is the phenomenon where humans show a preference for certain mappings between shapes and their corresponding labels/sounds.
One of the above objects shall be called a bouba, and the other a kiki
The above image of 2 theoretical objects is shown to a participant who is then asked which one is called a ‘bouba’ and which is called a ‘kiki’. The results generally show a strong preference (often as high as 90%) for the sharply-pointed object on the left to be called a kiki, with the more rounded object on the right to be called a bouba. This effect is relatively universal (in languages that commonly use the phonemes in question), having been noted across many languages, cultures, countries, and age groups (including infants that have not yet learned language very well!), although is diminished in autistic individuals and seemingly absent in those who are congenitally blind.
What makes this effect particularly interesting is less so this specific example, but that it appears to be a general phenomenon referred to as sound symbolism: the idea that phonemes (the sounds that make up words) are sometimes inherently meaningful rather than having been arbitrarily selected. Although we can map the above two shapes to their ‘proper’ labels consistently, we can go much further than just that if desired.
Which is a takete, and which is a maluma? Only you can decide.
We could, of course, re-draw the shapes a bit differently as well as re-name them: the above image is a picture of a ‘maluma’ and a ‘takete’. If you conformed to the expectations in the first image of this section, it’s likely that you feel the maluma is the left shape in this image as well.
We can ask questions about these shapes that go far beyond their names too; which of these shapes is more likely to be calm, relaxing, positive, or explanatory? I would certainly think the bouba and maluma are all four of those, whereas the kiki and takete seem more sharp, quick, negative, or perhaps even violent. If I was told that the above two shapes were both edible, I can easily imagine the left shape tasting like sweet and fluffy bread or candy, while the right may taste much more acidic or spicy and possibly have a denser and rougher texture.
Sound symbolism
The idea that large sections of our languages have subtle mappings of phonemes to meaning has been explored extensively over time, from Plato, Locke, Leibniz, and modern academics, with different figures suggesting their theorized causes and generalizations.
Some of my favorite examples of sound symbolism are those found in Japanese mimetic words: the word jirojiro means to stare intently, kirakira to shine with a sparkle, dokidoki to be heart-poundingly nervous, fuwafuwa to be soft and fluffy, and subesube to be smooth like soft skin. These are some of my favorite words across any language due to how naturally they seem to match their definitions and how fun they are to use (more examples because I can’t resist: gorogoro may be thundering or represent a large object that begins to roll, potapota may be used for dripping water, and kurukuru may be used for something spinning, coiling, or constantly changing. There are over 1,000 words tagged as being mimetic to some extent on JapanDict!).
For fun I asked some of my friends with no prior knowledge of Japanese some questions about the above words, instructing them to pair them to their most-likely definitions, and their guesses were better than one would expect by random chance (although my sample size was certainly lacking for proper scientific rigor). The phonestheme page on Wikipedia tries to give us some English examples as well, such as noting that the English “gl-” occurs in a large number of words relating to light or vision, like “glitter”, “glisten”, “glow”, “gleam”, “glare”, “glint”, “glimmer”, “gloss”. It may also be worth thinking about why many of the rudest and most offensive words in English sound so sharp, often having very hard consonants in them, or why some categories of thinking/filler words (‘hmm’… ‘uhhh…’) sound so similar across different languages. There are some publications on styles of words that are found to be the most aesthetically elegant, including phrases such as ‘cellar door’, noted for sounding beautiful, but not having a beautiful meaning to go along with it.
Sound Symbolism in Machine Learning with CLIP
I would guess that many of the above aspects of sound symbolism are likely to be evident in the behavior some modern ML models as well. The reason for this is that many recent SOTA models often heavily utilize transformers, and when operating on text, use byte-pair encoding (original paper). The use of BPE allows the model to operate on textual input smaller than the size of a single word (CLIP has a BPE vocab size of 41,192), and thus build mappings of inputs and outputs between various subword units. Although these don’t correspond directly to phonemes (and of course, the model is given textual input rather than audio), it’s still likely that many interesting associations can be found here with a little exploration.
To try this out, we can use models such as CLIP+VQGAN or the more recent CLIP-guided diffusion, prompting them to generate an image of a ‘bouba’ or a ‘kiki’. One potential issue with this is that these words could have been directly learned in the training set, so we will also try some variants including making up our own. Below are the first four images of each object that resulted.
four images of “an image of a bouba | trending on artstation | unreal engine”
four images of “an image of a kiki | trending on artstation | unreal engine”
The above eight images were created with the prompt “an image of a bouba | trending on artstation | unreal engine”, and the equivalent prompt for a kiki. This method of prompting has become popular with CLIP-based image generation models, as you can add elements to your prompt such as “unreal engine” or “by Pablo Picasso” (and many, many others!) to steer the image style to a high-quality sample of your liking.
As we anticipated, the bouba-like images that we generated generally look very curved and elliptical, just like the phonemes that make up the word sound. I have to admit that the kiki images appear slightly less, well, kiki, than I had hoped, but nonetheless still look cool and seem to loosely resemble the word. A bit disappointed with this latter result, I decided to try the prompt with ‘the shape of a kikitakekikitakek’ instead, inserting a comically large amount of sharp phonemes all into a single made-up word, and the result couldn’t have been better:
the shape of a kikitakekikitakeki | trending on artstation | unreal engine
Having inserted all of the sharpest-sounding phonemes I could into a single made-up word and getting an image back that looks so amazingly sharp that it could slice me in half was probably the best output I could have hoped for (perhaps I got a lucky seed, but I just used 0 in this case). We can similarly change the prompt to add “The shape of” for our previous words, resulting in the shape of a bouba, maluma, kiki, and takete:
the shape of a bouba (top left), maluma (top right), kiki (bottom left), and takete (bottom right)
It’s cool to see that the phoneme-like associations within recent large models such as CLIP seem to align with our expectations, and it’s an interesting case study that helps us imagine all of the detail that is embedded within our own languages and reality – there’s a lot more to a word than just a single data point. There’s *a lot* of potential for additional exploration in this area and I’m definitely going to be having a lot of fun going through some similar categories of prompts over the next few days, hopefully finding something interesting enough to post again. If you find this topic interesting, some words you may want to search for along with their corresponding Wikipedia pages include: sound symbolism, phonestheme, phonaesthetics, synesthesia, ideathesia, and ideophone, although I’m not currently aware of other work that explores these with respect to machine learning/AI yet.
Thanks for reading! I appreciate feedback via any medium including email/Twitter, for more information and contact see my about page
This Anime Does Not Exist was launched on January 19th 2021, showcasing almost a million images (n=900,000 at launch, now n=1,800,000 images), every single one of which was generated by Aydao‘s Stylegan2 model. For an in-depth write-up on the progression of the field of anime art generation as well as techniques, datasets, past attempts, and the machine learning details of the model used, please read Gwern’s post. This post is a more concise and visual post discussing the website itself, thisanimedoesnotexist.ai, including more images, videos, and statistics.
The Creativity Slider and Creativity Montage
Previous versions of ‘This X Does Not Exist’ (including anime faces, furry faces, and much more) featured a similar layout: an ‘infinite’ sliding grid of randomly-selected samples using the javascript library TXDNE.js, written by Obormot. Something more unique about Aydao’s model was that samples remained relatively stable, sometimes significantly increasing in beauty and detail as the ‘creativity’ value (see: psi) was increased all the way from 0.3 to 2.0. This led to the creation of the ‘creativity slider’ as well as linking every image to a page with a tiled layout showing every version of the image:
“The more entropy you give me, the more it makes me want to smile!”, 18 samples of image # X from creativity 0.3 to 2.0
One of the best and most common effects of higher creativity is better colorization, including shading, reflections, vibrancy, color diversity, and more
Another tile of seed 7087, showcasing stability with an increasingly interesting artistic style and details
Although the above two are among my favorite examples of creativity montages, many users found some other interesting things that increased creativity could do:
Sometimes it appeared as if ‘creativity’ was simply an alias for the increase in volume of a certain bodily area coupled with a proportional reduction of garment-covering surface area (seed 30700)
Sometimes increased creativity also leads to mitosis (seed 28499)
Sometimes you get… a lot of mitosis?
Selected artwork
The best way to demonstrate the stunning potential of this model is to show some of the samples that users have enjoyed the most:
The original thumbnail image for This Anime Does Not Exist: “Notice me, Onee-chan!”
Other earlier candidates considered for the website’s thumbnail (seeds: 1013, 4606, 8674, 8859)
Incidentally, it also seems that users love sharing images that are not the most beautiful, but the weirdest as well. The below four were among the most popular images on the website during the first few hours, when there was only n=10,000 of each image:
A montage of the interesting and popular results from images 3313, 7820, 4437, and 3103. Sample 3103 would be a particularly good album cover for a death metal band.
Collapsed images
Sometimes the result collapses enough to lead to an image that, although pretty, does not at all resemble the ideal target:
interesting but unintended results from samples 0544, 31975, 3997, 0557
Writing
In many cases the model will produce writing which looks distinctly Japanese, however upon closer introspection, is not legible, with each character closely resembling distinct counterparts in Japnese scripts, however diverging just enough to produce confusion with a lingering feeling of otherworldlyness.
Although some characters are easily recognizable, many are not, and are nonetheless *usually* combined in incoherent manners
Videos and gifs
As it’s possible to produce any number of images from the model, we can also use these images to produce videos and animated gifs. The primary style of this is referred to as an interpolation video which is produced by iterating through the latent variables frame by frame, transitioning in between different samples seamlessly:
Additionally, I decided to make a few videos that used a constant image seed, but modified only the creativity value instead (instructions on how I did this are here):
I chose this particularly wholesome sample to demonstrate a gif with creativity 0.3-2.0 and a frame difference of 0.01
Statistics and users
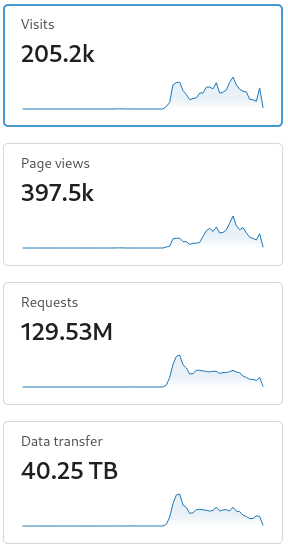
After the first day, the website had served over 100 million requests, using over 40TB of bandwidth:
First-day traffic statistics from CloudFlare’s Traffic Analytics
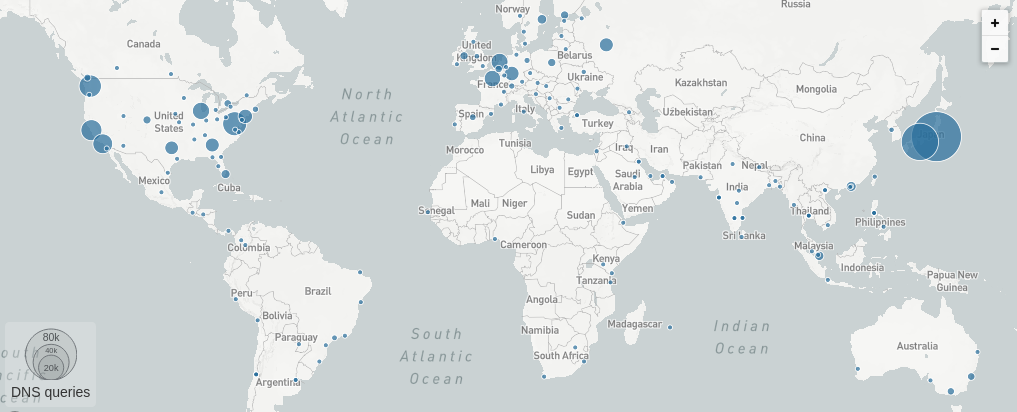
At launch, the largest contributor to traffic by country was the United States, followed by Russia, but over the next two days this quickly shifted to Japan.
A map showing which of Cloudflare’s data centers served the most DNS query results for the domain
Compare to similarly-trafficed websites, thisanimedoesnotexist.ai was relatively cheap, thanks to not requiring server-side code (serving only static content):
Domain ‘thisanimedoesnotexist.ai’: for two years from NameCheap: $110
Cloudflare premium, although not required, improves image load time significantly via caching with their global CDN: $20
Image generation: 1,800,000 images, 10,000 generated per hour with a batch size of 16 using a g4dn.xlarge instance, which has a single V100 GPU with 16GB of VRAM at $0.526 per hour on-demand: $95
“Accidentally” hosting the website from AWS for the first day, resulting in over 10TB of non-cached bandwidth charges: >$1,000 (via credits)
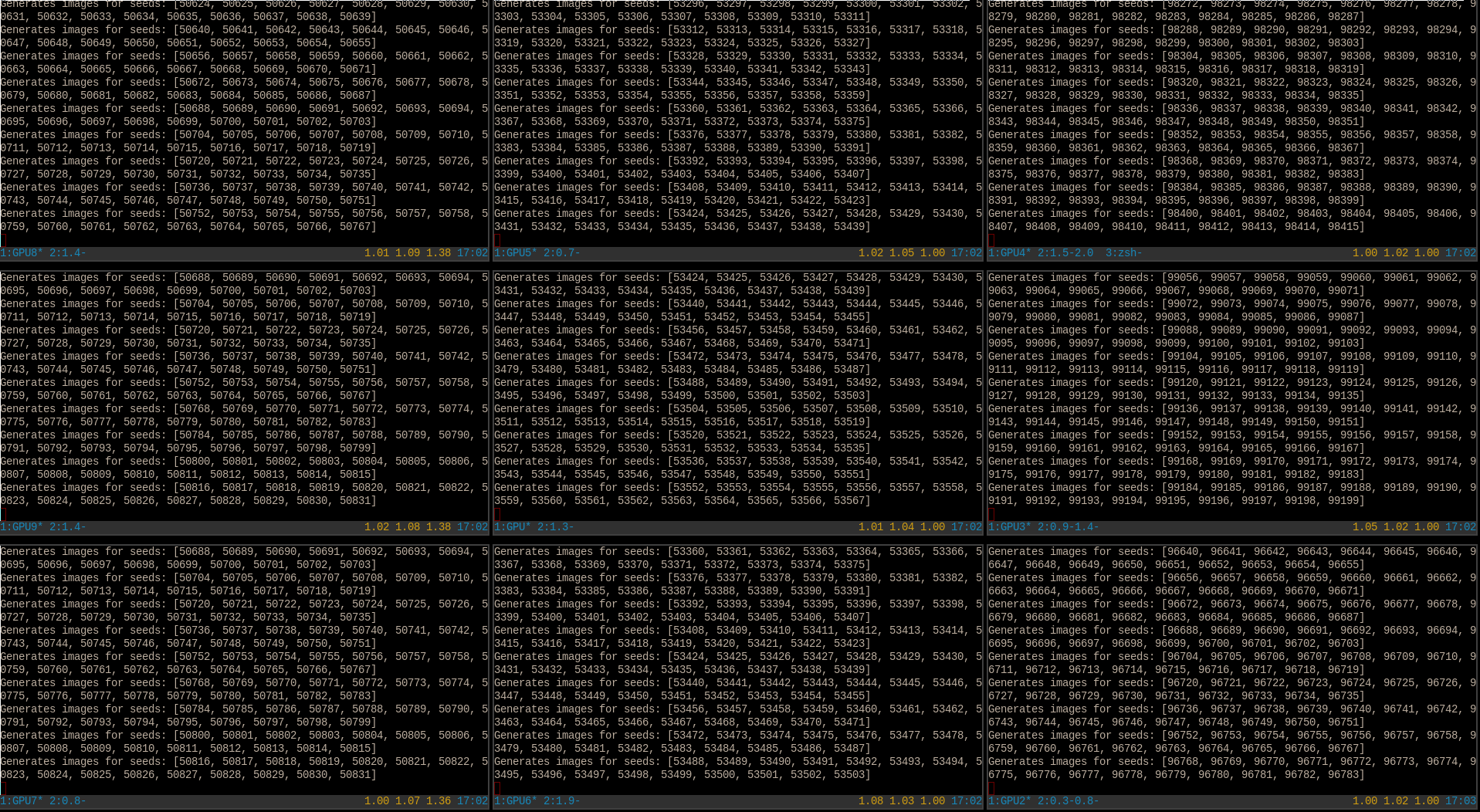
An image of what my desktop looks like while generating an additional million anime imagesWhat the access log for nginx looks like while serving >1,000 anime images per second
Yet another example of why to not use AWS for high-bandwidth content: AWS has some of the most expensive bandwidth at $0.09 per GB (luckily this was paid for entirely with credits and the migration off of AWS was complete in less than a day to a more sustainable provider)
Conclusions and the future
All in all, this was a fun project to put together and host, and I’m glad that hundreds of thousands of people have visited it, discussed it, and enjoyed this novel style of artwork.
If you want to read in-depth about the ML behind this model and everything related to it, please read Gwern’s post.
Thank you to Aydao for relentlessly improving Stylegan2 and training on danbooru2019 until these results were achieved as well as releasing the model for anyone to use, Obormot for the base javascript library used, TXDNE.js, Gwern for producing high-quality writeups, releasing the danbooru datasets, and and other members of Tensorfork including Gwern, arfa, shawwn, Skyli0n, Cory li, and more.
The field of AI artwork, content generation, and anything related is moving very quickly and I expect these results to be surpassed before the year is over, possibly even within a few months.
If you have a technical background and are looking for an area to specialize in, I cannot emphasize the extent that I’d strongly suggest machine learning/artificial intelligence: it will have the largest impact, it will affect the most fields, it will help the most people, it will pay the most, and it will cause you to be surrounded by the best and smartest people you could hope for.
Thanks for reading and I hope you enjoyed the website! For more about myself, feel free to read my about page or see my Twitter.